
Episodic Policy Search
We are developping new algorithms for episodic policy search, which are algorithms mainly focused on optimizing motion primitives based on the return. These algorithms are also often referred to black-box reinforcement learning as they do not use the temporal structure of the RL problem. While this is often less sample efficient then standard RL algorithms, it allows for more intuitive reward definitions and the resulting policies are also of higher quality. Our developments focus on more efficient policy updates as well as learning versatile behavior.
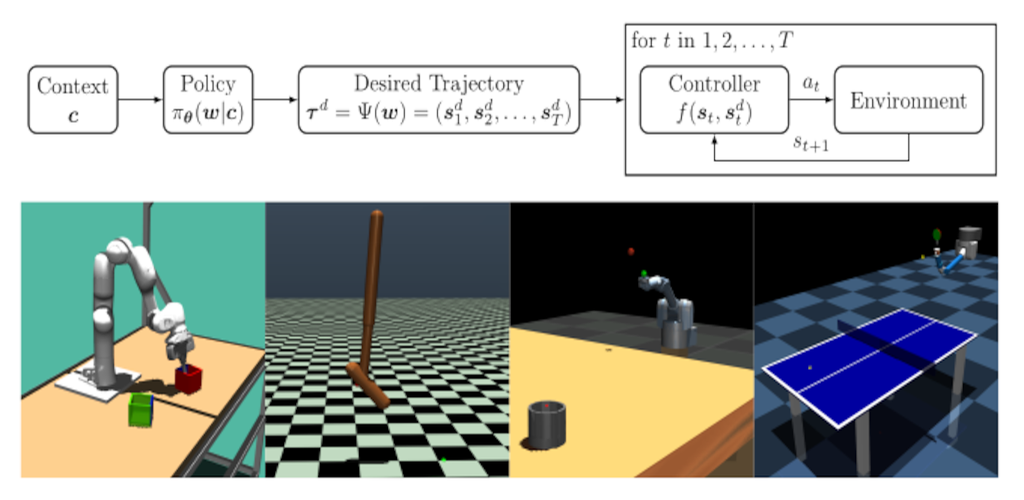
Episode-based reinforcement learning (ERL) algorithms treat reinforcement learning (RL) as a black-box optimization problem where we learn to select a parameter vector of a controller, often represented as a movement primitive, for a given task descriptor called a context.
more
We propose a new method which enables robots to learn versatile and highly accurate skills in the contextual policy search setting by optimizing a mixture of experts model. We make use of Curriculum Learning, where the agent concentrates on local context regions it favors. Mathematical properties allow the algorithm to adjust the model complexity to find as many solutions as possible.
A video presenting our work can be found here.
more