
Deep Reinforcement Learning
We are investigating new deep RL methods that use principled updates using information-theoretic trust regions that do not require so many code-level optimizations than typically used algorithms such as PPO. In terms of applications, we are looking into different manipulation scenarios with a high degree of uncertainty such as peg-insertion or searching for objects in a heap.
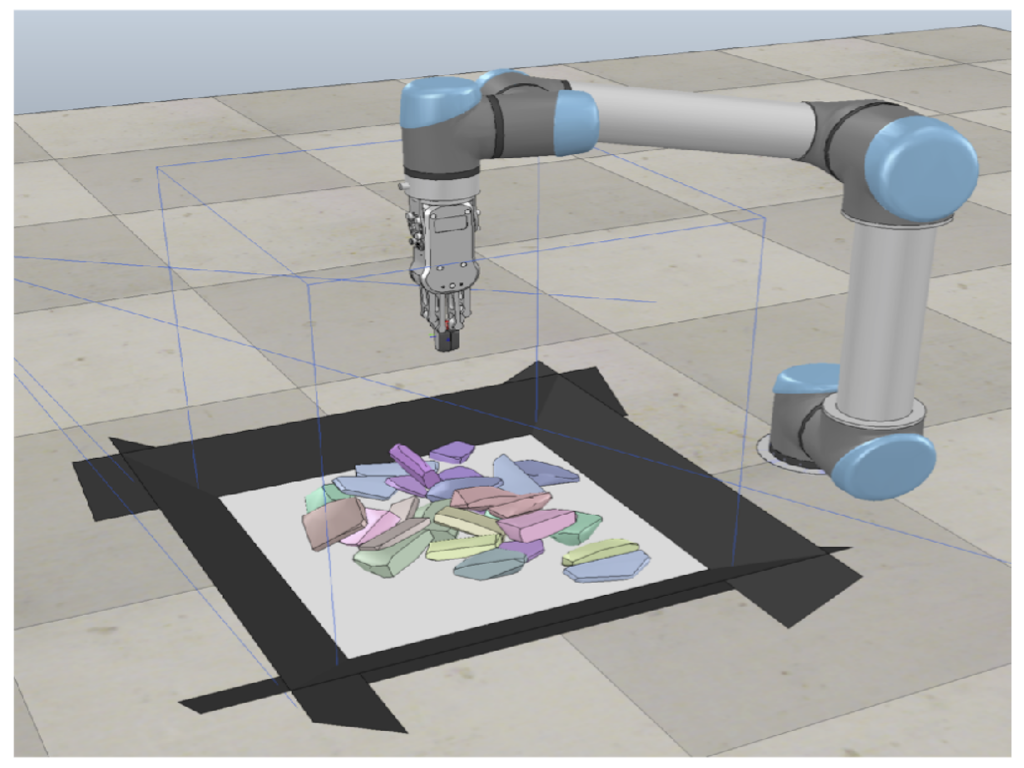
In this paper, we present a new approach for interactive scene segmentation using deep reinforcement learning. Our robot can learn to push objects in a heap such that semantic segmentation algorithms can detect every object in the heavily cluttered heap.
more
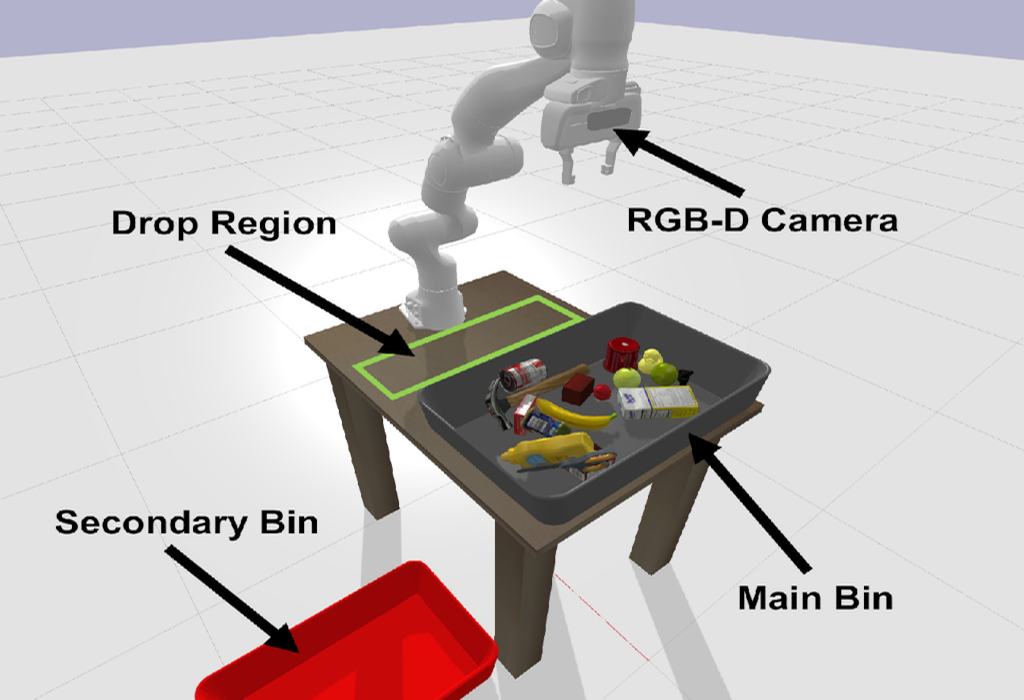
Mechanical Search (MS) is a framework for object retrieval, which uses a heuristic algorithm for pushing and rule-based algorithms for high-level planning. While rule-based policies profit from human intuition in how they work, they usually perform sub-optimally in many cases. We present am deep hierarchical reinforcement learning (RL) algorithm to perform this task, showing an increased search performance in terms of number of needed manipulation, success rate as well as computation time!
more
We developped a new residual reinforcement learning method that not just manipulated the output of a controller but also its input (e.g., the set-points). We applied this method to a real robot peg-in-the hole setup with a significant amount of position and orientation uncertainty.
more
Do you like Deep RL methods such as TRPO or PPO? Then you will also like this one! Our differentiable trust region layers can be used on top of any policy optimization algorithms such as policy gradients to obtain stable updates -- no approximations or implementation choices required :) Performance is enpar with PPO on simple exploration scenarios while we outperform PPO on more complex exploration environments.